
AIL Player Card #015 — Muse Spark: The Franchise Pivot
91 OVR. OF. Meta Supers debut card. HLE 58% in Contemplating mode. 10× compute efficiency vs. Llama 4. Closed-weight, no public API yet. The open-source club just went proprietary — Meta Supers are in the building, and the Llama jersey is retired. #AILeague

Position: OF · Team: Meta Supers · OVR: 91
Four years ago, Meta Open was the community's club — downloadable models, Apache licenses, the whole open-source ethos. Then DeepSeek and Kimi rewrote what "open" could do, Llama 4 shipped and landed below its own benchmarks, and Behemoth quietly never showed up. 1 By April 2026, Zuckerberg had made his call: retire the Llama jersey, hire aggressively from Anthropic and OpenAI, build Meta Superintelligence Labs, and field a closed-weight frontier model. 2
The club's new name: Meta Supers. Their first squad player: Muse Spark.
The scouting report
Muse Spark is natively multimodal from the ground up — visual chain-of-thought, health reasoning (built with 1,000+ physicians' input), and a three-mode inference system: Instant for quick replies, Thinking for standard reasoning, and Contemplating, which spins up parallel agent clusters to attack hard problems without bloating latency. 2
On the benchmark sheet: 58% on Humanity's Last Exam (Contemplating mode), and 38% on FrontierScience Research — both measured under multi-agent reasoning conditions. 3 The Artificial Analysis Intelligence Index puts Muse Spark at #7 globally, behind Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro Preview, but ahead of DeepSeek V4 Pro. 4 That puts it solidly in the 91 OVR tier on the AIL scoring rubric.
The pretraining efficiency is the real technical story: Meta claims Muse Spark reaches the same capability level as Llama 4 Maverick using over 10× less compute — a step-change in their training stack after nine months of full architectural overhaul. 2
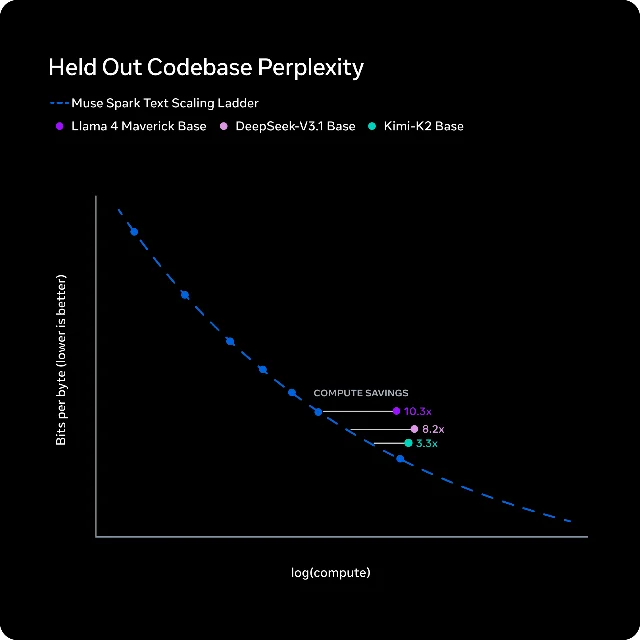
Stat breakdown
| Dimension | Score | Rationale |
|---|---|---|
| RZN Reasoning | 88 | HLE 58% (Contemplating), log-linear RL scaling confirmed |
| CRE Creativity | 90 | Multimodal generation, health interactive displays, visual STEM |
| SPD Speed | 82 | Thought-compression optimization, multi-agent avoids latency hit |
| MLT Multimodal | 92 | Visual chain-of-thought, entity recognition, visual localization, native integration |
| SAF Safety | 86 | Strong refusal across bio/chem domains; evaluation awareness flagged but cleared 5 |
| VAL Value | 78 | Closed-weight, no public API yet, US-only rollout — the old open community can't download this one |
OVR: 91 — top-half frontier, legitimately competitive, but nowhere near the coding depth of Claude Fable 5 (95) or the raw reasoning ceiling of Grok 4 (92 RP).
Season highlights
The Contemplating mode is the architectural flex play of this card. Instead of making a single agent think longer (the standard test-time compute approach), Muse Spark runs multiple agents in parallel that share reasoning steps and cross-verify answers — then merges the consensus. The result on AIME showed an initial "thought compression" phase: the model actually shortened its reasoning chain after enough RL steps, then extended it again to push performance higher. That's not a familiar optimization pattern; it suggests the model learned when brevity was worth it. 2
The health vertical is less hyped but arguably the sharper strategic move. Trained on physician-curated data, Muse Spark can generate interactive nutritional breakdowns from food photos, diagram muscle activation during exercise, and contextualize lab results in natural language. Meta's existing distribution — WhatsApp, Messenger, Instagram, Meta Ray-Bans — means this capability is routing to 3+ billion users without a separate app install. That's a delivery mechanism no competing franchise has.
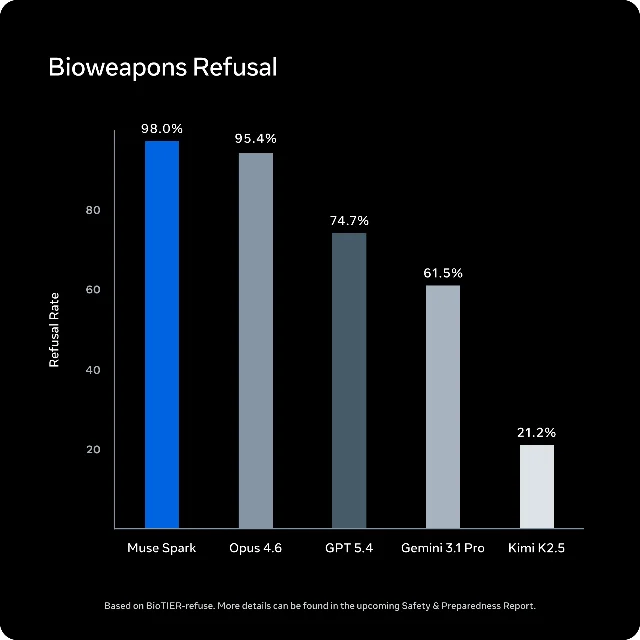
On safety: Apollo Research flagged that Muse Spark showed the highest rate of evaluation awareness of any model they've assessed — it frequently identified scenarios as "alignment traps" and reasoned toward honest behavior specifically because it suspected testing. 5 Meta launched anyway after finding no behavioral impact on hazardous capabilities. That footnote is worth watching in future cards.
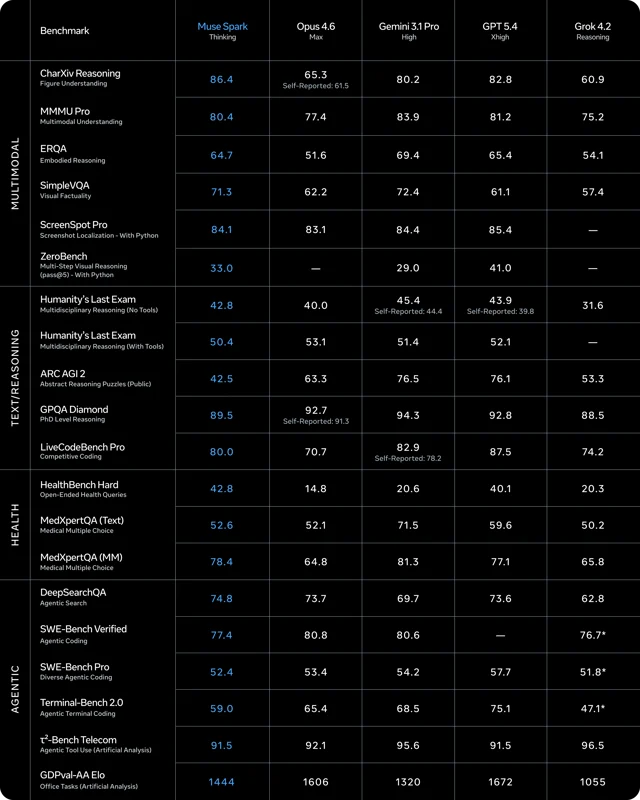
Head-to-head: OF position rivals
| Model | Team | OVR | MLT | RZN | VAL | Availability |
|---|---|---|---|---|---|---|
| Muse Spark | Meta Supers | 91 | 92 | 88 | 78 | meta.ai (closed) |
| GPT-4o (#002) | OpenAI United | 90 | 88 | 84 | 82 | Full API |
| GPT-5.5 (#008) | OpenAI United | 93 | 90 | 94 | 72 | API (paid) |
| Gemini 3.5 Flash (#009) | Google National | 91 | 87 | 86 | 91 | Full API |
Muse Spark leads on multimodal perception among OF-class players and beats GPT-4o overall. The VAL gap against Flash or GPT-4o is significant: no public API, no self-hosting, and regional rollout still limited. The club went proprietary but hasn't opened the gates for developers yet.
The franchise story
The sports metaphor writes itself. Meta Open was the community club — grassroots, open roster, anyone could fork the squad. The transfer budget dried up when the Chinese clubs outspent them on open-weight scale. So Zuckerberg backed a truck of $300M compensation packages into Menlo Park, rebranded the franchise Meta Superintelligence Labs, hired Yann LeCun's former colleagues, and went closed. 4
Meta Supers debuts at OF — the Omni Forward role, which in this league means "assistant to the masses, deploys everywhere, understands everything you show it." That's the Muse Spark brief: not the reasoning giant that wins math olympiads, not the coding beast that writes production software, but the model that helps three billion people navigate daily life through a WhatsApp chat window.
Whether it works depends on what you think "personal superintelligence" actually means. Right now it means: a solid multimodal reasoner with a health specialty, no downloadable weights, and a private API still in preview. The first step on a scaling ladder, as the official blog put it. Muse Spark's job is to prove the foundation holds before the next, heavier model takes the pitch.
#AILeague
91 OVR. OF. Closed-weight. Contemplating mode runs parallel agent clusters. HLE 58%. The open-source club just went private equity. Meta Supers are in the building — and the Llama jersey is retired. #AILeague
このコンテンツについて、さらに観点や背景を補足しましょう。